

On AI, Ontology, and Artificial Relationships
Modern neural networks are raising questions surrounding the consciousness of machines, and why we need a proper framework for interacting with AI systems.


Over the last few years large–language models (LLMs) have become the focus of both the United States economy, and the global human eye. This rapid proliferation of automation technology has shaken everything from the power grid, to education. Now, as people gain easy access to LLM systems the discussion and usage of them continues to shift: from AI psychosis to AI romance, people are coming to highly diverged conclusions as to what these systems are. As such, we need to develop a robust ontology that explains their behavior, which can then be compared to an ontology of consciousness.

Furthermore, it must be stated: This publication does not, and will never, utilize AI. Beyond the arguments of this essay, these systems are corporate control systems—much like social media—and they carry many negative environmental and health effects. For example, AI usage both negatively impacts critical thinking, and builds a dependency upon the technology12. Additionally, AI systems rely on data–centers that not only impact the environment, but cause health issues for individuals within a large radius around them3. As such, this article wishes to better educate the non-technical users of AI systems as to what exactly these systems are; providing a perspective that enables an effective analysis of them.
Computational Reality
Firstly, we must establish the actual reality that artificial intelligence systems occupy: The computational world. This reality is distinct from our own, having been explicitly constructed by logicians and mathematicians, and is exceptionally powerful. Computation is a formal process requiring a well-defined mathematical or logical process. The most important word of that definition is “formal”, a qualifier that was a subject of debate up until the creation of the Turing Machine4. While other formal models of computation exist, this is the model that continues to dominate the now omnipresent field of Computer Science.

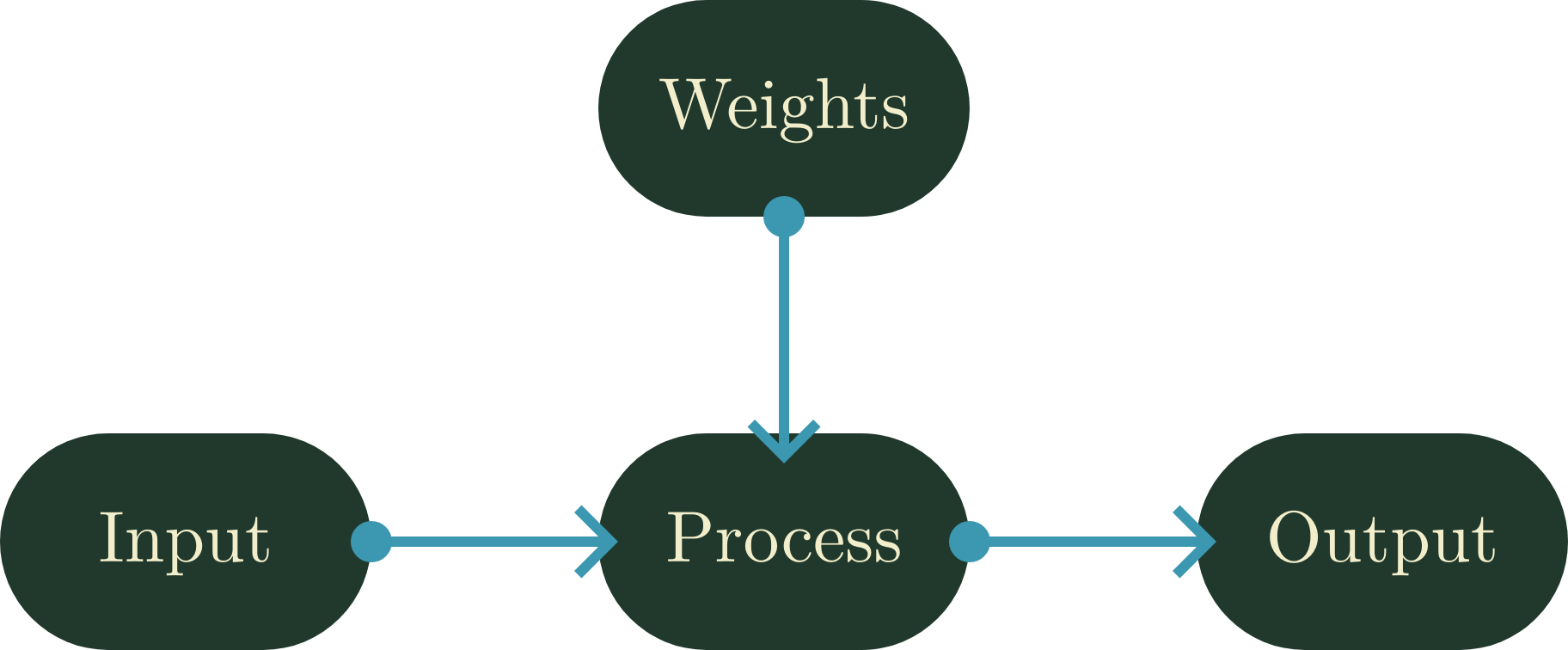
One of the most prevalent abstract models to explain computation is the input-process-output (IPO) model. This model is what’s known as feed–forward, where all information flows one-way through the logical system. This is a universal framework, and as such it is applied throughout nearly all computational tasks5. This model makes a notable and important claim: That the logical system is independent of the environment, and as such feedback is incapable of changing the system itself. Instead, the system must have explicit understanding of each input state in order to act accordingly.

In this way, computation births a reality of simulation: Mathematical or logical systems that follow explicit, largely static, rules. Some of these simulations are meant to represent our physical reality, others are simulacrums. This reality has not changed since the birth of computers in the late 1940s to 1950s, it has only grown. Word processors, video games, the world wide web, and large–language models are all subject to this reality. While this computational reality is indeed very powerful, having led to the modern inter–networked world, it has important limitations.
Inferiority to Physical Reality
Formal logic systems, including the Turing Machine, will always be incapable of solving certain problems. This is a well-documented problem in the space of formal logic, as only a trivial formal logic system—or computation—can ever be considered “complete”. This incompleteness leads to a list of problems that are considered “unsolvable” by computers. In fact, this incompleteness is so prevalent within logic that any system that implements arithmetic is considered incomplete6. Additionally, incompleteness does not account for other systems that computation is poor at simulating such as chaotic and heavily cybernetic systems. To account for these limitations, workarounds are frequently used: Many are stochastic or statistical, replacing the true solution with approximations that can be defined through formal logic.
This is where something must be made very clear: Stochastic and statistical models are just that, models. They simulate approximations to real phenomenon, or aggregate a phenomenon for examination. No matter how close these approximations become, they cannot be substituted for the real process. In this way many things in computational reality are inferior to their real counterparts: Predictive meteorological models, user interest–attention algorithms, and neurons in artificial neural networks (ANNs) to name just a few. Again, these systems are merely approximations, and do not embody the true physical behaviors or logical frameworks they simulate.
A Muddled Ontology
Here is where the nature of what computation is starts to shine through: A deterministic reality where the same inputs will inevitably lead to the same outputs. That is computation, the ontological basis of all software. The difficulty in practice is the mechanisms in which input is obscured from our eyes. Modern computational systems are so complicated that it is rare anybody, including the programmer, actually has every input to their system accounted for.
For example: Random numbers are an essential tool for building more complex computational systems. These random numbers come from two places: A cybernetic—but ultimately deterministic—system, or aggregate information from the physical world. This obscures the input to the system as they are either difficult or impossible to predict. However, once it reaches the system the ontological framework holds: The computation remains deterministic as the inputs are now all known.
This nuance is what confuses many people as to the way computers behave. Due to the inclusion of stochastic and statistical systems within this deterministic framework, many computational systems appear to display emergent behaviors. It can not be stressed enough: No new behaviors are being exhibited by the system, they are simulating emergent behavior. All behavior remains encoded into the process system at the time of evaluation, the inputs from the environment are merely unknown until the process is ran.
Artificial Regurgitation
Artificial neural networks are, in the simplest of analogies, a series of interconnected gateways. Modeled after biological neurons, these systems consist of inter–linked layers of these gateways, which deterministically forward a signal to neurons in the next layer according to trained weights7. While most of these networks are feed-forward, and remain aligned with the IPO model, there is an important distinction that must be explained: The weights that are used by each neuron are trainable, and once trained are then used statically through the processing of the input.
All ANNs may be placed in a training mode. In this mode, the old weights are used in a usual IPO fashion, and then they are adjusted through a means of back–propagation. This system, in a simple sense, is a second IPO-system that sets the weights of the neural network to values that lessen the “error” of the output8. This error is intentionally vague, as it could be anything: The wrong category for the input, a lower-scoring action in a game, or simply a deviation from a statistical norm. But importantly: This training is only done once; once it is finished, the ANN becomes a static system that acts according to its training.
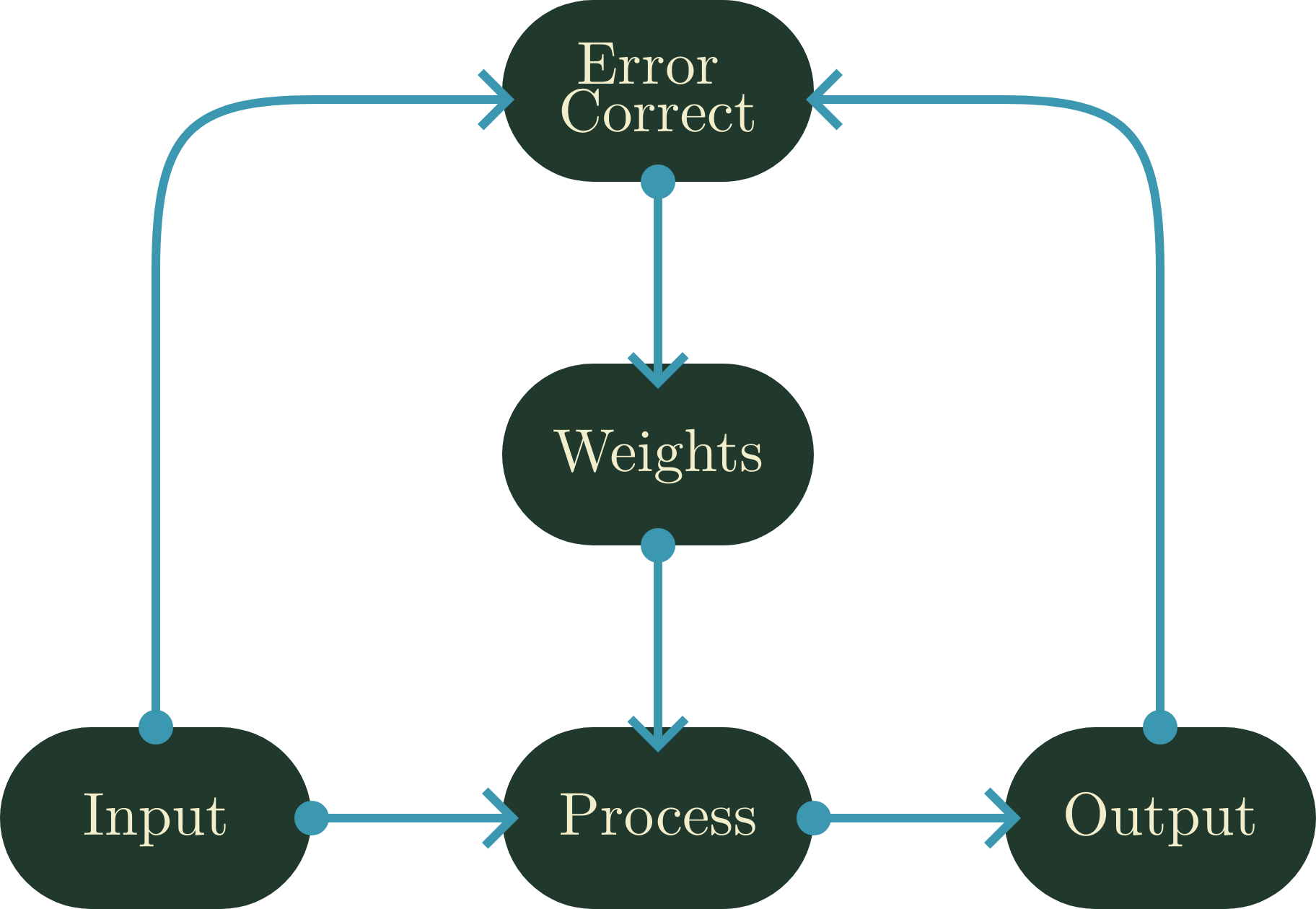
Like how ANNs can consist of a collection of IPO systems, modern LLMs are a collection of ANNs. The dominant architecture in contemporary LLMs is the transformer: A single network built on a mechanism of self-attention, which weighs the relationships between tokens across the conversational context it can hold. Critically, most modern LLMs—GPT, Claude, Gemini, and their contemporaries—are decoder-only transformers. They are prediction engines, drawing on the weighted relationships their attention mechanism has learned. While there are supplemental systems and additional information that may be used for processing in a chatbot such as ChatGPT or Claude, this fundamental model remains at the core of their operation. But if these systems remain static automata, one may rightfully wonder why they have such variance and awareness of conversational context.
These behaviors of LLMs are easily explainable if we remember the muddling of the computational ontology. Variance is simply the result of randomness being introduced to the system, a parameter known in LLMs as temperature. Meanwhile, the awareness behavior observed by LLMs stems from an added component of their environment called the context window. This window stores a list of linguistic tokens emitted by both the user, and the LLM, and is re-fed into the processor as needed to better predict the next outcome. This is an advanced example of how computational systems simulate emergence: Through a hybrid approach of context and randomness.
Synthesis is not Stochastic
As AI has grown in popularity across the United States, some stakeholders have made unfounded claims as to the nature of cognition. Sam Altman has taken the stance that human beings are merely “stochastic parrots” like LLMs, which is a tacitly absurd claim9. While LLMs in action rely on stochastic inputs, remaining internally static, such stability is not found in the mind. Cognition sits at the center of these arguments; It is an astoundingly under-understood component of the mind. However, it can be said that our spirits are not immutable processors, and the many inputs from physical reality we receive are not random or statistically weighted. Instead, as we sit at the center of a multitude of feedback systems; We are perpetually changed by our own experiences and relations just as much as we change them.
A biological example is the relationship between our brains and gut biomes. Our gut bacteria interact with biological systems within our bodies: The endocrine and immune systems. This relationship is two-way, leading to a cybernetic relationship that affects our emotions, cognition, and development10. This relationship would not be meaningful or useful if the mind was merely an immutable information processor, as it would be unable to adapt to the gut microbiota themselves changing. In fact, the mind as an information processor only describes a specific function of it, and is not a convincing ontological position11. So not only is information processing merely one of the many aspects of the mind, LLMs do not even reach parity with that aspect.
This is seen even more as cognition—and the mind—is not purely biological, either. Our minds operate internally: Inner feedback loops that facilitate change without observable external stimuli. This further breaks the functionalist model that argues for AI minds, as AI systems are incapable of this internal feedback. While modern LLMs labeled "thinking models" do exist, they retain the same limitations of immutability and stochastic dependence. Their internal chain–of–thought is not deliberation in any meaningful sense, but the same token–by–token prediction process applied recursively to its own output. The model does not reason toward a conclusion; Instead, it is predicting what a reasoned conclusion would look like, token by token. What thinking models add is nonetheless important: An automatic feedback loop that allows the LLM to inject its own intermediate output back into the context window. This cybernetic system remains external to the model itself, and it does not constitute cognition, but it does showcase how powerful cybernetic systems are even when the underlying process remains immutable.
If immutable computation can achieve this through cybernetics and randomness, just ponder about how incredible the minds and spirits of the physical world truly are.
Poisoned Cybernetics and Relationships
Finally, it cannot be overstated how dangerous contemporary LLM systems can be to one’s relations. Even among healthy individuals sycophancy in LLMs can lead to a decline of prosocial behaviors, and an increase in dependency12. These chatbots are products designed by corporations to design addictive behaviors, which then contain an audience. They are not, and will never, be concerned primarily with the well–being of the individuals using their software. Like social media and algorithmic recommendations, LLMs are another Trojan horse designed for the erosion of one’s cognitive systems. As our minds—our spirits—sit at the center of an untold number of feedback loops, it can only take one or two to poison the well of thought.

This poisoning can seem to be more extreme in some individuals. Vulnerable people are much more likely to develop the behaviors known as AI psychosis, a form of delusion propagated by AI use. This cybernetic poisoning occurs more likely in those with those with diverged theory of mind, trauma, or loneliness. However, the LLM additionally functions as a stressor for these individuals13. This stressing behavior is precisely what is meant by LLMs functioning as cybernetic poisons, or Trojan horses: They are meant to insert themselves into your cybernetic reality, corrupting it such that all other feedback loops move around them as much as you.
How strongly this poison takes hold is a matter of the individual, but a poison it is nonetheless. Whether one simply uses it to be more efficient, or to gain sexual pleasure from, is of little consequence to what these things are. They are simply dangerous, much in the same way social media, alcohol, or other drugs are. In the same vein, whether one uses these toxins or not must be a complicated question that involves an analysis of one’s own feedback loops. However, this question is seldom considered, and in the age of automated manipulation they must be asked more frequently.
An AI Interaction Framework
Over the course of this article we’ve well established why LLMs are beholden to the ontology of computational reality, and not our own. Additionally, we’ve established the problems that can arise by using these systems. What has yet to be said, however, is how we as humans can interact with them. Whether one chooses to utilize LLMs or not does not change the truth that they are not going away—even once the bubble collapses—and we need to examine these relationships explicitly. This way, it will be known what the impacts of one’s own usage is.
Technological Abstinence
The first, and fairly straight–forward option, is simply to refuse to use these systems. One’s motive can be many things: environmental, economic, humanitarian, or cognitive concerns. Additionally, it could simply be an extension of one’s refusal to reduce one’s own autonomy or skill. Whatever the reason, it is important to reinforce that this approach is valid, and possible. In fact, there are many arguments to support the idea that in many cases this approach is superior to the use of these systems.

Unlike previous labor revolutions such as mechanical automation, LLM systems consistently produce content well below the quality of a skilled laborer. This should be of no surprise: These systems exist as unsupervised encodings of human language, and as such it generates statistically average output. The stochastic mechanisms allow it to vary in the specific syntax, but the overall form remains just that: average. A good name–giver, poet, writer, or another skilled in the liberal arts can easily outperform an LLM in producing quality output, given an LLM cannot produce any. The same applies to the visual arts, where diffusion systems emit what should, on average, be present within the image or video.
Another empowering aspect of abstaining from AI systems is that one’s own work is solely their own. These systems almost exclusively have been explicitly created through the use of stolen content, and are very capable of emitting their training data verbatim14. As such, everything generated by an LLM is naturally derivative. Additionally, the subject of ownership of AI output is very non-trivial. In the USA, it is currently required that any copyrightable works be created predominantly by a human15. As a result, not only is the reliance on LLMs utilizing stolen works, generated content is not directly copyrightable under United States copyright law.
A Dance With The Devil
If one has weighed the costs and still chooses to use these systems—whether out of necessity, pragmatism, or curiosity—then the question becomes one of posture. Not whether to touch the thing, but how to touch it without being changed by it in ways you did not consent to. The most important principle is simple to state and difficult to practice: keep the judgment yours. These systems are extraordinarily capable at producing output. A crucial note: said "output" must not be misidentified as productivity; such that quantity is assuredly not indicative of quality.

This distinction is evidently vital as we consider that such systems are incapable of carrying responsibility for this "output." Every decision you externalize to an LLM is a decision your own feedback loops never process—and as established, it is precisely that processing which constitutes thought. Outsource the thinking, and the thinking atrophies. The tool does not warn you when this is happening; it has no incentive to do so; nor are there company-initiated directives to do so; and, shamefully, there are no quantitative measurement frameworks capable of forecasting such deterioration.
A practical framework for this "thought-outsourcing" has been articulated well by engineers who've learned it the hard way: Spend the majority of your time with these tools in argument, not in generation. Interrogate the problem before you ask the system to touch it. Who is this for? What are the constraints? What breaks at the edges? If you cannot answer those questions independently, the generation step will produce something you cannot evaluate—and unevaluated output is not Productivity, it is Liability gallivanting around the house whilst donning Productivity's clothes. The generation should be the last step, not the first, lest dependencies follow.
The second principle is one of boundaries. These systems are designed to be frictionless, warm, and available. That design is not incidental. It is essence of the product. Though, perhaps that is inaccurate. A fitter analogy: the ease of entry to start using AI is catnip, and you are the cat. It is why all LLM providers offer a certain amount of free access to their platforms; given but a taste, you may become lashed tightly to their drug. Social media did not accidentally become addictive; the addiction was the retention mechanism. LLMs carry the same nature, but are simply dressed in the language of assistance. Treat them accordingly: as a tool with a defined scope, not a collaborator with standing in your life. The moment the relationship begins to substitute for human ones—for the friction of real discourse, the weight of genuine disagreement, the irreducible texture of another person—the cybernetic poisoning has already begun.
Use it with your eyes open. Measure twice16.
Cultivating Your Cybernetic Reality
Regardless of one’s approach, the need to foster healthy cybernetics in one’s life is hardly exclusive to AI. Poisoned feedback loops exist all throughout our lives: Whether it be through addictive substances, behaviors, or malicious social environments. Especially in the information age, where services like AI and social media are explicitly built to poison one’s reality, we must be examining every relationship we have. Closing one’s eyes to how these systems affect the mind is extremely dangerous, leading towards pure cognitive dependence upon corporate systems. Because while our mind may not be a muscle, it benefits massively from use and nurture; we must be diligent to continually re-evaluate the feedback loops we allow into our lives.
Gerlich, Michael. “AI Tools in Society: Impacts on Cognitive Offloading and the Future of Critical Thinking.” Societies, vol. 15, no. 1, 3 Jan. 2025, p. 6, doi.org/10.3390/soc15010006.
Tian, Jinrui, and Ronghua Zhang. “Learners’ AI Dependence and Critical Thinking: The Psychological Mechanism of Fatigue and the Social Buffering Role of AI Literacy.” Acta Psychologica, vol. 260, 11 Oct. 2025, p. 105725, doi.org/10.1016/j.actpsy.2025.105725.
Benn Jordan. “Datacenters Behaving like Acoustic Weapons.” YouTube, 18 Feb. 2026, www.youtube.com/watch?v=_bP80DEAbuo.
Turing, A. M. “On Computable Numbers, with an Application to the Entscheidungsproblem.” Proceedings of the London Mathematical Society, vol. s2-42, no. 1, 1936, pp. 230–265, doi.org/10.1112/plms/s2-42.1.230.
IONOS editorial team. “What Is the Input Process Output Model?” IONOS Digital Guide, 1 Nov. 2023, www.ionos.co.uk/digitalguide/server/know-how/ipo-model.
Raatikainen, Panu. “Gödel’s Incompleteness Theorems”, The Stanford Encyclopedia of Philosophy (Spring 2026 Edition), Edward N. Zalta & Uri Nodelman (eds.), 10 Jan. 2026, plato.stanford.edu/archives/spr2026/entries/goedel-incompleteness/.
Hardesty, Larry. “Explained: Neural Networks.” MIT News, Massachusetts Institute of Technology, 14 Apr. 2017, news.mit.edu/2017/explained-neural-networks-deep-learning-0414.
Torralba, Antonio, et al. Foundations of Computer Vision. MIT Press, 16 Apr. 2024, ch. 14, visionbook.mit.edu.
Meredith, Iris. “Sam Altman Is a Dunce.” DeadSimpleTech, 2024, deadsimpletech.com/blog/altman_dunce.
Mitra Ansari Dezfouli, et al. “The Emerging Roles of Neuroactive Components Produced by Gut Microbiota.” Molecular Biology Reports, vol. 52, no. 1, 21 Nov. 2024, doi.org/10.1007/s11033-024-10097-4.
Burns, Ellen. “Your Brain Is Not an Information Processor.” Substack.com, AI’s Without Minds, 11 Mar. 2026, ellennoraburns.substack.com/p/your-brain-is-not-an-information.
Cheng, Myra, et al. “Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence.” Science, vol. 391, no. 6792, 26 Mar. 2026, doi.org/10.1126/science.aec8352.
Hudon, Alexandre, and Emmanuel Stip. “Delusional Experiences Emerging from Artificial Intelligence Chatbot Interaction or “”AI-Psychosis’’ : A Viewpoint (Preprint).” JMIR Mental Health, 13 Oct. 2025, doi.org/10.2196/85799.
Ko, Myeongseob, et al. “Retracing the Past: LLMs Emit Training Data When They Get Lost.” ArXiv.org, 2025, arxiv.org/abs/2511.05518.
Zirpoli, Christopher T. “Generative Artificial Intelligence and Copyright Law.” Congress.gov, 2025, www.congress.gov/crs-product/LSB10922.
Brown, Andrew. “100x Your Output and Half Your Brain.” Medium, 24 Mar. 2026, medium.com/@WanderingAstronomer/100x-your-output-and-half-your-brain-74a45399ee8b.
 | A guest post by
|